Understanding Driver Fatigue Detection Systems
Among the factors potentially contributing to the occurrence of road traffic incidents is driver fatigue, which may accumulate during the journey or be present even before its commencement. A common sign of driver fatigue is drowsiness.
To mitigate the impact of driving fatigue, several driver fatigue detection systems have been developed recently. These safety technologies aim to prevent accidents caused by driver tiredness during driving. On our side, we have implemented several systems of this type to compare their effectiveness. The most comprehensive tracking system is based on the use of the dlib library for facial landmark detection (68-point set) – more about it here. It detects the eyes (open-closed, calculated using the eye aspect ratio from characteristic points), the mouth (open-closed, similarly using the mouth aspect ratio), head rotation (left-right), and head tilt (down-up) based on Euler angles — all of which serve as indicators of drowsiness.
In an effort to potentially improve the accuracy of detecting these indicators, we also worked on the similar project based on the use of a convolutional neural network (CNN). The goal was to create a driver fatigue detection system to determine the duration during which a human eye is closed. The project was implemented on Python.
Convolutional Neural Networks (CNNs) are a special type of neural network with multiple layers, known as convolutional layers. CNNs enable the learning of complex features and make more accurate predictions about the content of visual materials. CNNs are applied in various fields, including facial recognition, autonomous driving, medical prototyping, and more.
The implemented Python project creates a driver fatigue (drowsiness) warning system. We develop solutions using different approaches to select the best technology. In this project, a cascade Haar classifier is employed to detect faces and eyes with the help of OpenCV. Subsequently, the driver’s state is predicted based on a publicly available CNN model.
Mathematical Model and Algorithm of the Project
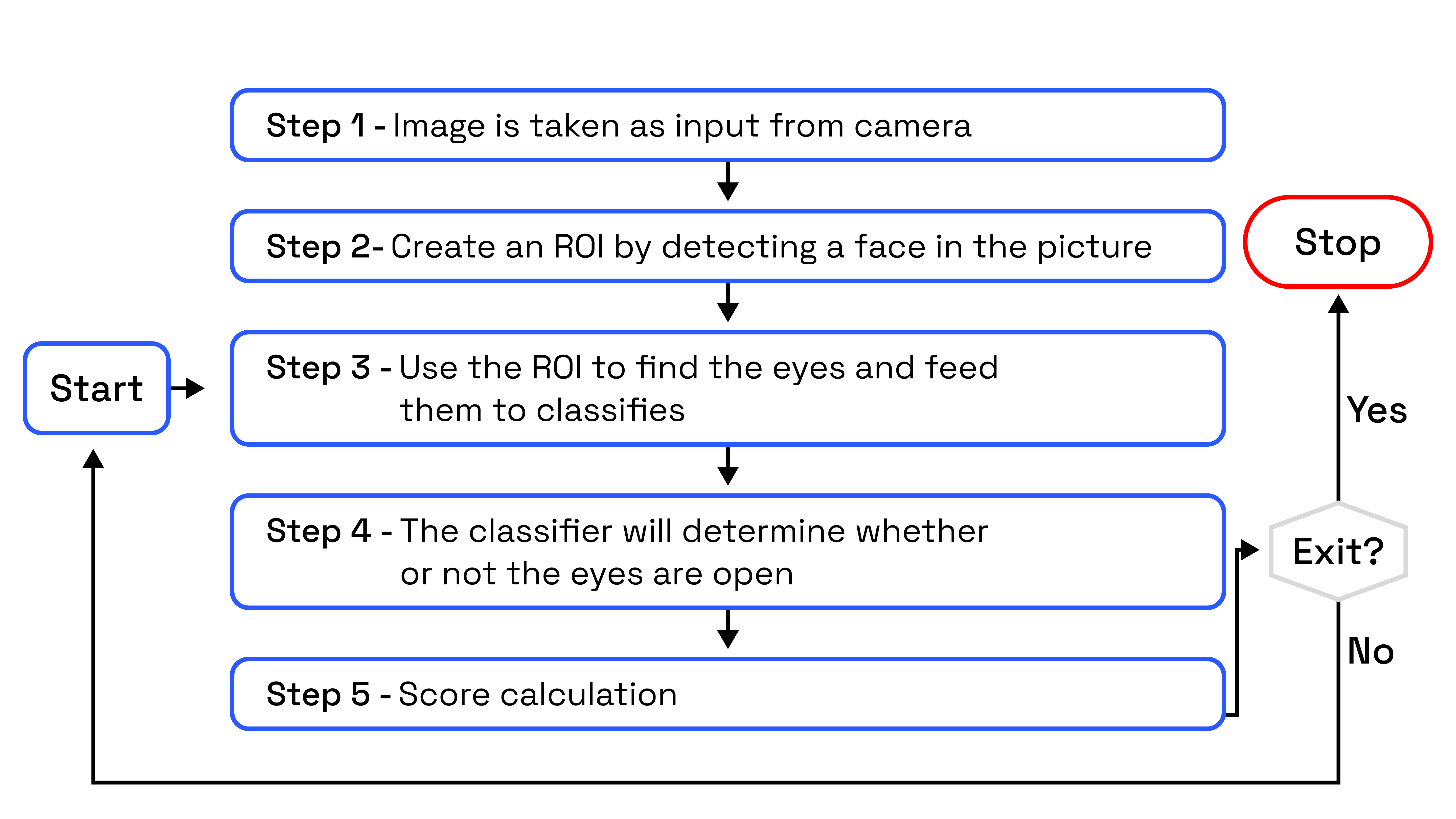
This Python-based system leverages OpenCV to capture images from a webcam and feed them into a Convolutional Neural Network (CNN), a deep learning model that categorizes human eyes as either “open” or “closed.” The project algorithm is illustrated in the following generalized block diagram.
The approach taken in this Python project is as follows:
Step 1: Capture an image from the camera as input data.
Step 2: Detect the face in the image and create a Region of Interest (ROI).
Step 3: Identify human eyes within the Region of Interest and input them into the classifier.
Step 4: The classifier categorizes human eyes as open or closed.
Step 5: Calculate an assessment to determine whether the driver is fatigued.
For this Python project, a webcam is required for image capture. Additionally, you need to install Python and then use pip to install the necessary packages: OpenCV-Use for face and eye recognition, TensorFlow (Keras uses TensorFlow as a backend, so it’s required for building the classification model), and Pygame for playing the warning signal.
The project utilizes the CNN model called cnnCat2.h5, which is publicly available. The dataset includes approximately 7000 images of human eyes categorized into two states: “open” and “closed,” captured under various lighting conditions. The model’s structure is constructed using Keras through a Convolutional Neural Network (CNN). CNN is a specialized type of deep neural network particularly well-suited for image classification. It typically consists of an input layer, an output layer, and hidden layer, which can comprise multiple layers. Convolution operations are performed on these layers using filters, which conduct two-dimensional matrix multiplication of layers and filters.
The CNN model structure includes the following layers:
- Two convolutional layers (32 nodes, kernel size 3),
- A third layer (64 nodes, kernel size 3),
- A fully connected layer (128 nodes),
- The final layer – is also a fully connected layer with 2 nodes (open/closed eyes).
In all layers, except for the output layer utilizing Softmax (a logistic function for the multiclass case applied to a vector), the Rectified Linear Unit (ReLU) activation function is employed. ReLU is one of the most popular activation functions used in both shallow and deep learning models. This function is versatile and suitable for various tasks without requiring extensive computational resources. It replaces all negative values with zero and passes positive values unchanged. The gradients for positive values remain non-zero, facilitating effective gradient propagation and weight updates during training. This property allows the network to learn from more sparse representations of data, reducing the risk of overfitting.
Project Implementation (with Python Code Fragments)
In the project code, it is necessary to import the required packages:
import cv2
import os
from keras.models import load_model
import numpy as np
from pygame import mixer
import time
import keyboard
import sys
Obtaining face and eye images using Haar cascades (these XML files are also available publicly):
face = cv2.CascadeClassifier('haar cascade files/haarcascade_frontalface_alt.xml')
leye = cv2.CascadeClassifier('haar cascade files/haarcascade_lefteye_2splits.xml')
reye = cv2.CascadeClassifier('haar cascade files/haarcascade_righteye_2splits.xml')
Additionally, loading the CNN model:
model = load_model('models/cnncat2.h5')
For capturing input images, a webcam is used. To access the webcam, an infinite loop is executed to capture each frame – the cv2.VideoCapture (0) method provided by OpenCV is used to access the camera and set the capture object (cap) – cap.read () – each frame is read, and the image is stored in a frame variable.
The face is detected in the image, and a Region of Interest (ROI) is created. To detect human faces in the image, it is necessary to first convert the image mode to grayscale since the OpenCV algorithm for object detection requires input images in grayscale. Therefore, the object can be detected without color information. The project uses the Haar cascade classifier to detect faces: face = cv2.CascadeClassifier (the path to the Haar cascade XML file), and then faces = face.detectMultiScale (grayscale) used to perform the detection. Then, a detection array is created with x and y coordinates and height (width of the object’s bounding rectangle). Now, these detections are iterated over, and a bounding box is drawn for each face: for (x,y,w,h)in faces:cv2.rectangle(frame,(x,y), (x+w, y+h), (100,100,100), 1).
The normal (working) state of the driver:
Next, the human eye is identified within the Region of Interest (ROI) and input into the classifier. The process of detecting human eyes is analogous to the detection of human faces. Firstly, cascade classifiers for the eyes are set up, and then left_eye = leye.detectMultiScale (gray) is used to detect human eyes (for the left eye, and similarly for the right eye). Now, data for the human eye is extracted from the entire image. This is achieved by extracting the bounding rectangle of the eye, and then this code is used to extract the eye image from the frame: l_eye =frame[ y : y+h, x : x+w ] l_eye contains only the image data of the left eye. This will be loaded into the CNN classifier, which will predict whether the eyes are open or closed.
lpered = (model.predict(l_eye) > 0.5).astype("int32")
lpred = np.argmax(model.predict(l_eye), axis=-1)
(lpred[0] == 1) – the eye is open, lpred[0] == 0 – the eye is closed)
Similarly, data from the right eye is extracted into r_eye.
The classifier categorizes the eyes as open or closed. Since the model must be started with the correct size, some operations need to be performed before the image is input into the model. First, r_eye = cv2.cvtColor (r_eye, cv2.COLOR_BGR2GRAY) is used to convert the color image to grayscale. Then, since the model was tested on images of size 24×24 pixels, the image needs to be adjusted to 24×24 pixels using cv2.resize (r_eye, (24,24)). The data is standardized (normalized) for better convergence: r_eye = r_eye / 255 (all values are in the range from 0 to 1).
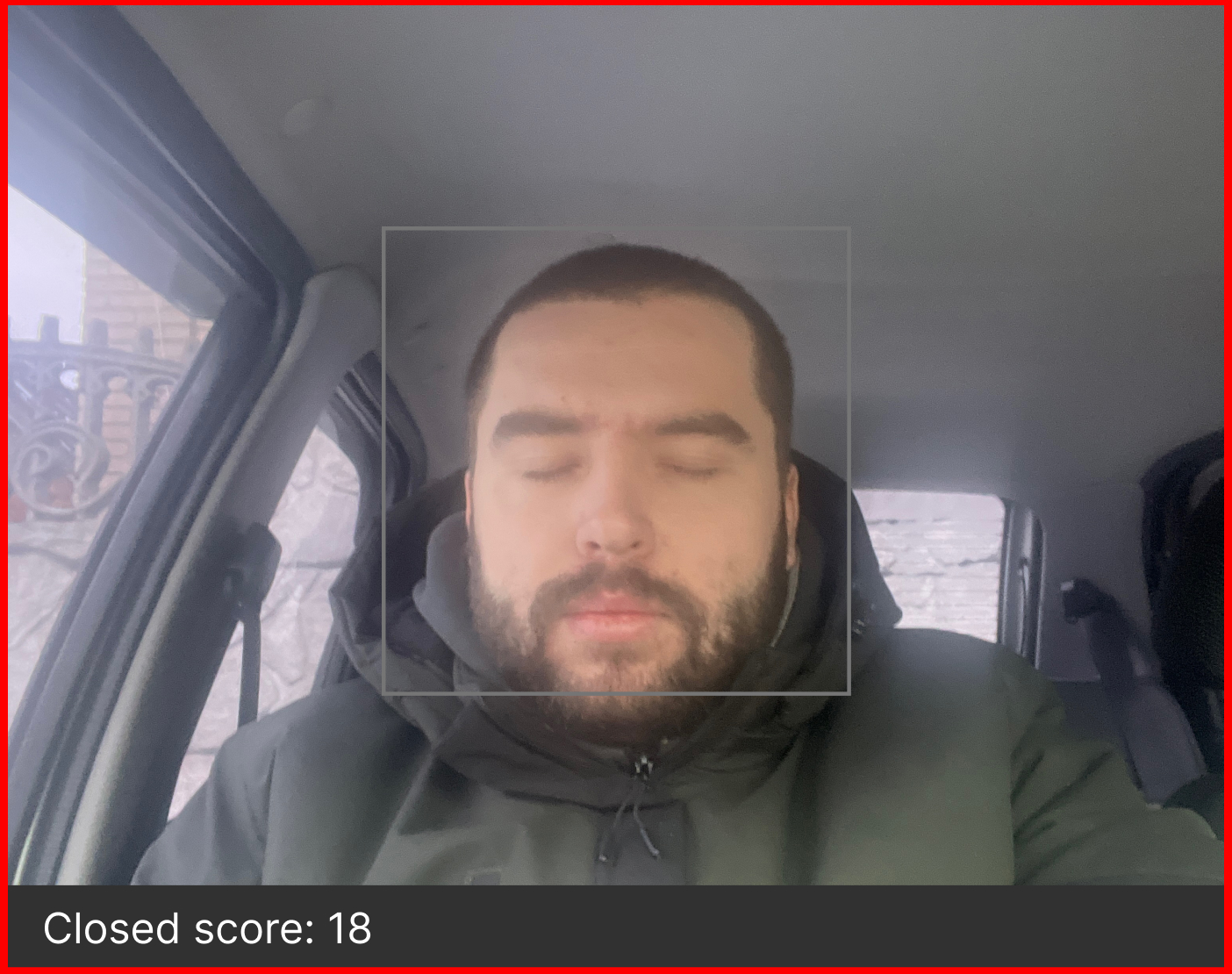
Driver fatigue (drowsiness) is determined based on the calculated score to assess whether the driver is tired. The score is essentially a metric used to determine how long the driver keeps their eyes closed. Therefore, if both eyes are closed, the score will continue to rise, and when the eyes are open, the score will decrease. The cv2.putText () function is used to overlay the result on the screen, displaying the driver’s status in real-time: cv2.putText(frame,“Open”, (10, height-20), font, 1, (255,255,255), 1, cv2.LINE_AA ). The threshold value is determined using the following method: for example, if the score is greater than 10, it means the driver has kept their eyes closed for a prolonged period (threshold is set to 10 – can be adjusted based on empirical data accumulation).
if(rpred[0] == 0 and lpred[0] == 0):
score=score+1
(When both eyes are closed, the score increases; if they are open, it decreases)
if(score > 10):
cv2.imwrite(os.path.join(path,'image.jpg'),frame)
try:
sound.play()
except:
Pass
If the threshold value for closed eyes is exceeded, the sound.play() function is used to trigger an alarm signal.
Сonclusion
The implemented project helps prevent accidents caused by driving in a drowsy state. By using the Haar cascade classifier in OpenCV for face and eye detection, and then applying a CNN model to predict the driver’s status, the drowsy cases can be effectively addressed. Further development can turn this detection system into hardware with enhanced features.
The project efficiently identifies driver fatigue based on the criterion of drowsiness (eyes closed for a certain threshold time), and serves as a primary indicator for assessing the danger of driving. The developed solution detects the drowsiness condition more effectively than other implementations. However, we believe a more comprehensive approach to driver fatigue detection is crucial (based on the dlib library – more about it here. Combining both of these projects is evidently necessary.
At IT-Dimension, we are well-positioned to develop comprehensive systems for monitoring various aspects of human condition, including fatigue. By utilizing advanced technologies such as Machine Learning frameworks, Neural Network architectures and Libraries for collecting facial landmark points, we can offer a wide variety of monitoring solutions and companion apps tailored to different needs.